

在发布开源可商用大模型Llama 2之后,Meta日前正式发布该模型的编程版本Code Llama,极大弥补了之前在代码任务上表现不佳的短板,进一步拉近了与闭源的GPT模型的差距,测试效果直追GPT-4。
值得一提的是,就在Code Llama发布的两天前,OpenAI开放了GPT3.5的微调功能,允许开发者和企业根据自己的需求定制模型。作为目前开源和闭源领域综合实力最强的两个大模型,这不免存在些许你追我赶的竞争意味,甚至是有一丝火药味?
编程作为大语言模型最重要的应用领域之一,也是当前几乎所有技术产品和服务都离不开的,对该能力的优化和改进具有重要意义。
本次发布的Code Llama是在Llama 2的基础上,通过特定的代码数据集进一步训练而来,支持C++、Java、Python、PHP、Typescript(Javascript)、C#和Bash等众多流行语言,依然是开源可商用。
Code Llama对编程专家和初学者都非常有用,无论是用专业的编程语言还是用自然语言(如普通话)来描述编程需求,Code Llama都能理解,并很好地生成相应的代码或与代码相关的解释。这极大降低了开发门槛和效率。
多版本模型覆盖更多特定场景需求根据Meta的博文,Code Llama分为7B、13B和34B三个不同参数版本,可满足不同的服务和延迟要求。每个版本的模型都使用了500B tokens与代码相关的数据进行训练。
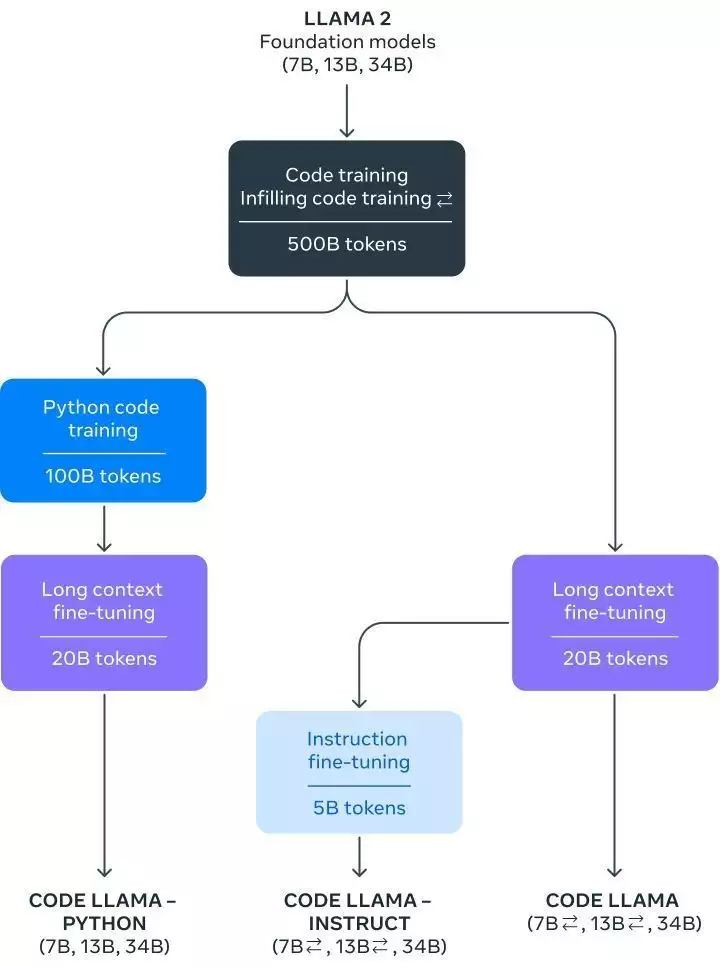
最小的7B参数模型可以在单个GPU上运行,响应速度快,适用于需要低延迟的任务。但相比更大的模型,在代码生成或理解方面不够精确。最大的34B模型能提供最佳的编码辅助,在复杂的编程任务中表现最好。但需要更多的计算资源,延迟也可能更高。中等规模的13B 参数模型在性能和延迟之间提供了一个平衡点。另外,7B和13B的模型经过了中间填充(fill-in-the-middle,FIM)功能的训练,能够理解如何在一段现有的代码中添加新代码,可以直接用于自动代码补全等任务,无需额外的设置或训练。
Code Llama支持一次性理解并记住最多10万token的上下文,强大的文本处理能力对于处理大型代码库或长篇文章都非常有用。比如,当开发者需要处理大量代码时,可以将整个代码片段一次性“喂”给Code Llama。
值得一提的是,为了满足更多特定需求,Meta还进一步针对Python和自然语言指令微调了两个Code Llama的变体,分别称作Code Llama-Python和Code Llama-Instruct。
Python是目前最受欢迎的编程语言之一,在多个领域有着广泛应用,特别是在数据科学、机器学习等领域。一个专门针对Python的模型能更准确地生成和理解Python代码,提高模型在处理相关任务时的性能。
另一个子版本Code Llama-Instruct更注重理解自然语言指令,非常适合那些不是很熟悉编程但又有这方面需求的用户。这个版本更容易理解用自然语言给出的指令,也就是更适合非专业用户,除了可以用于代码生成,也能胜任其他与代码相关的自然语言处理任务,如代码注释或文档生成。
通过提供更多垂直的子版本,Code Llama模型能够覆盖更广泛的用例和人群,满足不同场景下的特定需求,更容易获得竞争优势。
不过,Meta也有在博文中说明,由于Code Llama更专注于代码任务,因此并不适合作为聊天或写文章等日常语言任务的基础模型,它主要是为了帮助人们编程或处理代码问题而设计的。
性能和安全性双领先
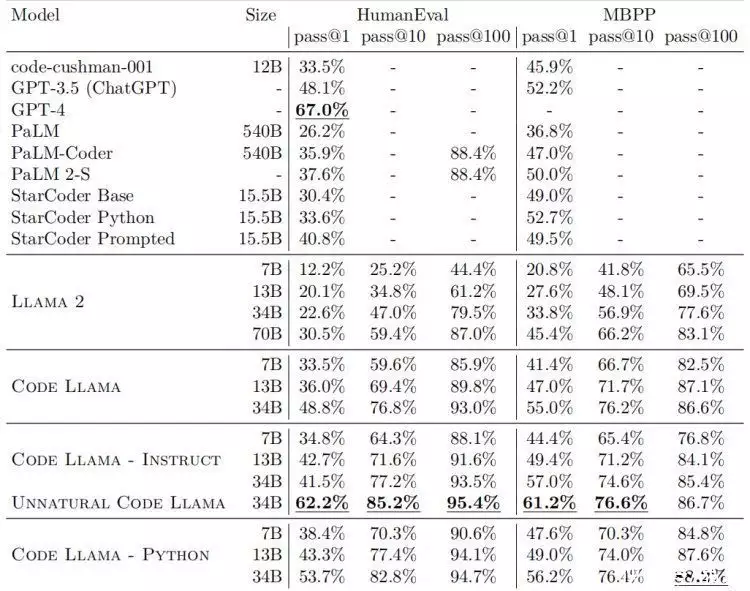
而有关Code Llama的具体性能,在多个代码基准测试中,Code Llama达到了开源模型中最先进的性能。Code Llama所有模型在MultiPL-E上都优于其他公开可用的模型。34B参数版本在HumanEval上得分为53.7%,在MBPP上得分56.2%,这与ChatGPT(GPT 3.5)相当,优于其他所有开放解决方案。
在安全性上,Meta采取了许多措施,为做评估,研究者特意用一些指令请求恶意代码,测试Code Llama是否会生成不好的输出。并对比ChatGPT做了同样的测试。结果显示,Code Llama更不容易生成有问题或者有害的代码。
Meta还发表了一篇详细介绍Code Llama的论文(题为Code Llama: Open Foundation Models for Code),披露了Code Llama开发的细节以及如何进行基准测试等信息。
值得一提的是,在Meta发布的论文中出现一个名为“Unnatural Code Llama”的模型(见上图),各项评分都非常之高,但该模型只在论文中一闪而过,Meta并未提及,或许后续Code Llama会迎来进一步增强。
更多详细内容可以参看论文:
https://arxiv.org/abs/2308.12950